

Context-Aware Retrieval: From Late Chunking to Contextualized Embeddings
Is your RAG still running on context-agnostic embeddings? No wonder your retrieval is losing context.

In my previous article - Before Agents, There Was RAG - I explored the baseline techniques that improve retrieval pipelines and gave a deep dive into Anthropic’s contextual retrieval.
The big takeaway back then: contextual retrieval was a meaningful step forward. By manually enriching each chunk with document-level cues, you could reduce ambiguity and improve retrieval quality. It proved that context matters.
But I also pointed out the caveats:
Token cost & latency: You repeatedly feed long documents to a large LLM to position many chunks. (Auć!)
Throughput: Indexing becomes slower and harder to parallelize.
Operational complexity: You’re maintaining augmentation code, caches, and prompt contracts. Practical walkthroughs show workable pipelines, but the operational overhead is non-trivial.
There are, however, alternatives..
Don’t get me wrong - contextual retrieval through metadata augmentation or context summaries still works well and brings real value. But there are two other approaches that can deliver even stronger results. They do come with trade-offs, and not every organization will be able to adopt them (I’ll explain why later).
The key difference is that they don’t rely on users manually adding or supplying contextual information. These approaches are:
Late Chunking
Contextualized Chunk Embeddings
Late Chunking
Traditional chunking: split → embed → store.
The problem: each chunk embedding is blind to the larger document (or context-agnostic - sounds cool, so I’ll mention it).
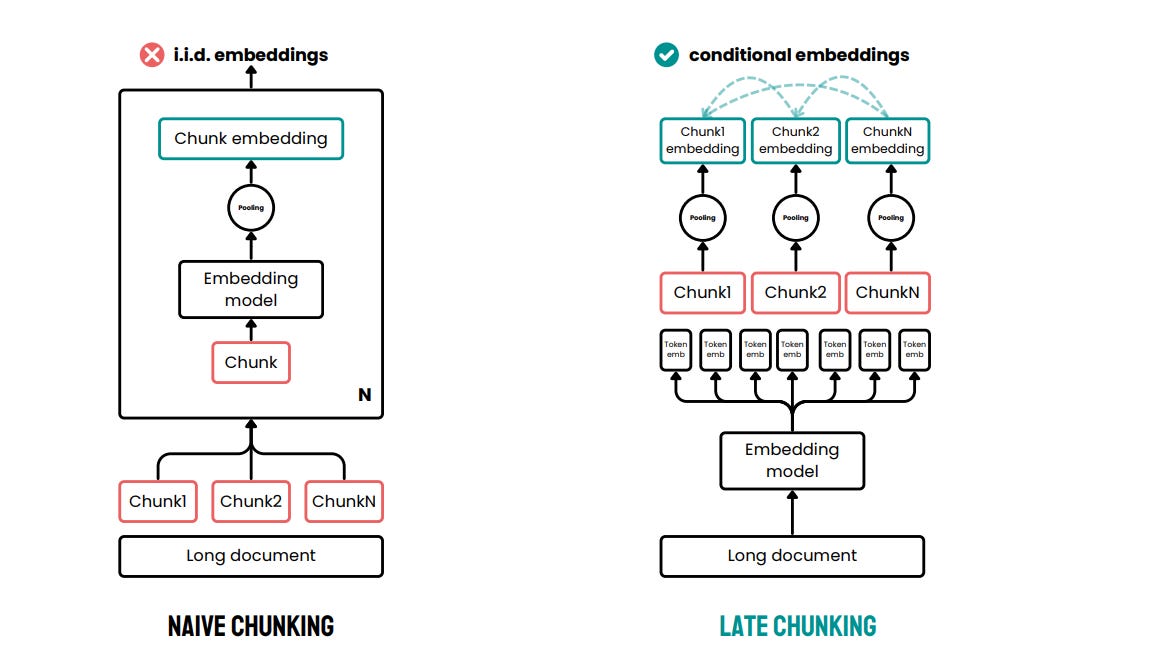
How late chunking works
First, the model processes the entire document - turning the full text into token embeddings that carry complete context.
Only afterwards, right before mean pooling, the text is split into fragments. In other words: first you get token embeddings, and only then you do “chunk pooling.”
As a result, the embedding of each fragment reflects not only its own content, but also information from the whole document.
Example outcome: sentences that did not contain the word “Warsaw” showed much higher cosine similarity to the query embedding “Warsaw” with late chunking compared to traditional chunking.
So instead of “split first → then embed,” we do: “embed the full text token-by-token → then average the relevant ranges into chunks.”
Result → each chunk inherits document-level context without re-feeding the entire document.
Late chunking is a technique for creating semantic representations (embeddings) of small text fragments without losing context from the full document. Unlike the traditional approach, chunking happens after the entire text has been processed by the model - that’s why it’s called “late.”
Pros
Higher retrieval accuracy
Cons
Embedding long documents is compute-heavy
Limited by the max context length of the embedding model
Late Chunking provides a high level of context preservation by embedding the entire document first, creating enriched chunk embeddings. However, it’s constrained by the context window of the embedding model.
Which models can we use for late chunking?
Not every embedding model is suitable. In late chunking, the key factor is the encoder type. The model must be:
a long-context embedding model,
supporting mean pooling,
and giving access to token-level embeddings (last_hidden_state),
so that you can perform pooling later on the selected spans.
From my research, the best fit is jina-embeddings-v3 - it supports 8192 tokens, delivers excellent performance on MTEB and retrieval benchmarks, and is ready for late chunking.
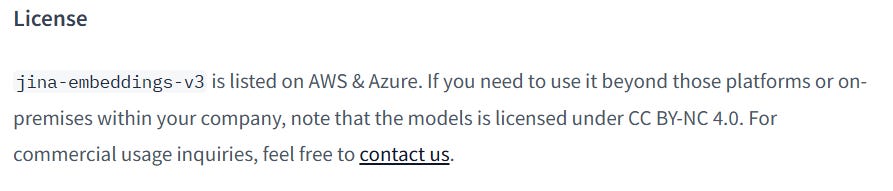
Caveat: the jina-embeddings-v3 model is available on Hugging Face (and likely in other repos), but it’s licensed under CC BY-NC 4.0 (Creative Commons Attribution–NonCommercial 4.0).
If you plan to use it in a commercial project, it’s best to contact Jina AI directly about licensing.
But don’t worry - towards the end of this article I’ll also cover Dewey, an open-source model that enables a private and elegant implementation of late chunking.
Long Late Chunking
Long Late Chunking
For very long documents (longer than the model’s maximum context length), the authors propose an approach using macro-chunks:
The document is split into larger fragments with some overlap between them.
Each macro-chunk is processed separately, and then the token embeddings are merged—so the entire document is still represented with full context.
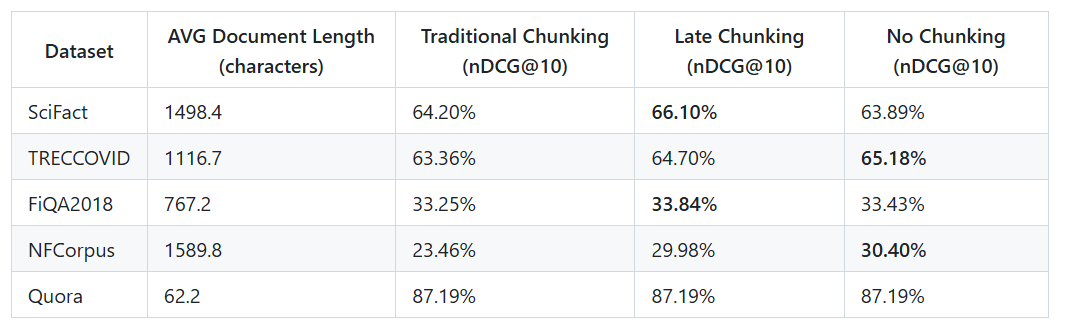
Below you can see evaluation results on various BeIR datasets, comparing traditional chunking with the late chunking method performed by Jina AI. For splitting texts into chunks, they used a simple strategy: breaking the text into 256-token strings. Both the traditional and late chunking experiments used the jina-embeddings-v2-small-en model.
Across different text retrieval benchmarks (e.g. BeIR), late chunking consistently outperformed traditional chunking:
On average, ~3–3.6% relative improvement
Equivalent to about +1.5–1.9 percentage points in nDCG@10
👉 In short: nDCG@10 tells you how close your top 10 retrieved results are to the ideal ordering.
Contextualized Chunk Embeddings
Contextualized chunk embeddings capture the full context of the document without requiring the user to manually or explicitly provide contextual information. This leads to improved retrieval performance compared to isolated chunk embeddings, while remaining simpler, faster, cheaper than other context-augmentation methods.
Late chunking is a clever engineering trick, but there is something better. What if the model itself was trained to make chunk embeddings that already understand their place in the document?
That’s exactly what Voyage AI’s voyage-context-3 does.
Why it matters:
Produces chunk-level embeddings enriched with global context in one pass.
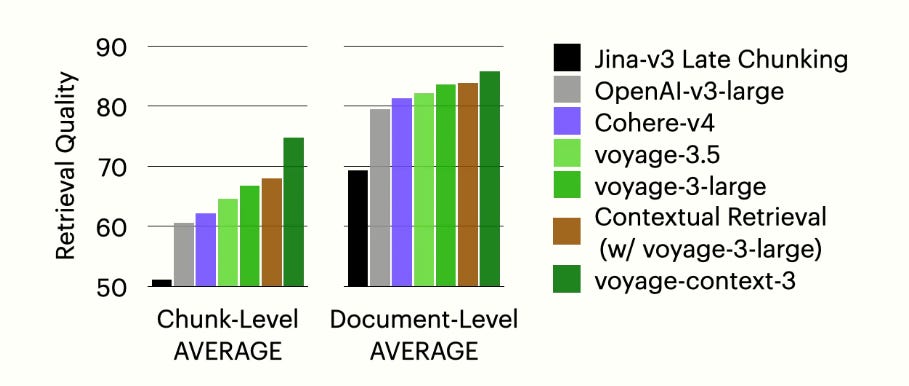
On retrieval benchmarks, it outperforms:
OpenAI-v3-large and Cohere-v4 by 14.24% and 12.56%, and 7.89% and 5.64%, respectively.
Context augmentation methods Jina-v3 late chunking and contextual retrieval by 23.66% and 6.76%, and 20.54% and 2.40%, respectively.
Plug-and-play replacement for existing embedders.
Caveat:
voyage-context-3is proprietary and not open-source - it’s currently accessible only through the Voyage AI API.
Other Voyage models (such as voyage-3, voyage-3-large, and domain-specific variants) are already available on AWS and Azure Marketplaces, allowing enterprises to deploy them within private network environments (via SageMaker or Azure VNet) to ensure end-to-end data privacy. Hopefully, we’ll see voyage-context-3 join them in the future.
Voyage = API only → you always send your data to their servers.
According to Voyage, the data is not used for training, but you still need to rely on their policy and trust their assurances.
Fully Private Alternatives
For organizations that cannot (or prefer not to) send data outside their environment, there are strong open-source options. One standout is:
Dewey (infgrad/dewey_en_beta)
Dewey is a long-context embedder (up to 128k tokens) trained with chunk-alignment so it can produce both global document representations and fine-grained chunk vectors in one shot - conceptually close to contextualized chunk embeddings. Technical report and model weights are public.
Long-context embedder (up to 128k tokens),
Trained with chunk-alignment to produce both chunk-level and global embeddings,
Model weights available on Hugging Face, under the MIT license - a very permissive license allowing commercial use, modification, and redistribution without restrictions
Closing Thoughts
Contextual retrieval was an important milestone - it proved that adding context makes retrieval work better. But it came with baggage: high token costs, slower pipelines, and added engineering overhead.
Late chunking took a clever shortcut: let the model read the whole document before slicing it into chunks. That gave fragments richer context and better accuracy, though at the price of heavier compute and context window limits.
Contextualized embeddings push things further still. Instead of engineering tricks, models like voyage-context-3 are trained to “bake in” global context, delivering stronger results out of the box.
And for teams that need full control, open-source options like Dewey bring long-context, self-hosted embeddings that rival proprietary APIs - without giving up privacy.
The direction seems clear - retrieval is moving away from context-agnostic fragments toward embeddings that carry both local detail and global awareness.
Thanks for reading! In my next post I’ll dive into fine-tuning embeddings.👌
I’d love to hear your thoughts! Have you tried late chunking or contextualized embeddings? Drop a comment or reply directly🫡